
这一节将介绍oTree编程涉及的基础概念,官方文档中对这些概念都进行了全面的介绍,这里只针对部分基础的和常用的进行介绍,深入了解这些概念还需要阅读官方文档。
1. 写 oTree 用到的语言
虽然前面介绍了python及oTree的安装,但编写otree程序并不只是涉及python一种语言,还涉及到三种语言,分别是HTML(超文本标记语言)、CSS(层叠样式表)、JavaScript。其中python用于后端,后三种语言用于前端。下面对这些语言及他们在oTree程序中承担的任务进行简单的介绍
python语言:用于完成后端变量定义、数据交互、计算等功能的语言。与z-Tree不同的是,oTree有明确的编程思想,即面向对象编程思想。
关于什么是面向对象编程,可以参考这个简短的介绍:【8分钟搞懂面向对象编程 | 面向过程vs面向对象 | OOP | 封装 继承 多态】(注:这个UP主也有一个python入门课程)
简单来说,面向对象是将某个任务涉及到的不同事物、属性、方法进行抽象分类,与之相对的是面向过程编程,即将完成某个任务划分成不同步骤,编写完成每一步骤的代码。
就写oTree而言,对python语言的深入了解不是必须的,但熟悉python肯定有好处,有必要了解的基础内容有以下一些:数值类型和数学计算、逻辑运算(与、或、非)、数据结构(元组、列表、字典、集合)、控制语句(循环和条件)、函数和模块、面向对象和类、字符串等。python的相关教程的基础部分一般都会包含以上这些内容。
HTML:一种标记语言而非编程语言,通过一套标记标签(markup tag)用于描述网页内容,即哪个地方是标题、哪个地方是文本内容、哪个地方插入图片等。 常见常用的一些标签:
<p>
段落标签
</p>
<ul>
<li>无序列表</li>
</ul>
<ol>
<li>有序列表</li>
</ol>
<div>
块级元素,可用于组合其他元素的容器,也常用于文档布局。<span>这个则是内联元素,用来组合行内元素比如文本</span>
</div>
<h3>下面是一个带表头的表格</h3>
html表格:
<table>
<tr> <!--定义表格的行-->
<th>月份</th> <!--定义表格的表头-->
<th>销售</th>
</tr>
<tr>
<td>一月</td> <!--定义表格的单元格-->
<td>1000</td>
</tr>
<tr>
<td>二月</td> <!--定义表格的单元格-->
<td>2000</td>
</tr>
</table>
CSS:描述HTML文档样式的语言,说明每个HTML文档中每个元素应该如何显示,比如字体是否加粗、标红,按键的位置、大小等等
JavaScript:web编程语言,用于说明HTML上每个元素的动态变化、进行输入验证和数据传输等,比如当点击某个按键的时候某个文字变红、在前端验证输入的答案是否正确等
前端页面是直接和被试交互的,因此页面的设计很可能会影响到被试的决策,这说明编写过程中必须认真考虑前端页面的呈现。oTree本身提供的前端框架能很大程度上减少对这些语言的使用,简化了前端页面的编写过程,但是这也损失了很多自由度。当需要对前端页面进行一些调整的时候,不可避免地需要使用三门语言。这三种语言深究起来也是一个大坑,所幸上手比较容易,不一定需要精通,只要了解基础的内容,能读懂上面提到的网站中的程序例子即可。
实际上,oTree在生成前端页面的时候使用了一个非常流行的前端框架Bootstrap,这个框架提供了许多有用的组件和JS插件,oTree一些自带的按键、输入框等都是基于Bootstrap而来的。
2. oTree 文件与程序架构
文件
为了了解oTree的文件类型和程序架构,我们先创建一个新的oTree程序文件夹
选定储存的位置(假设储存路径为E盘下的EXP文件夹),点击VSCode左上角File菜单→Open Folder打开EXP文件夹,在VSCode中打开Terminal(终端,可用快捷键Ctrl+~或点击界面左下角的图标打开,其他快捷键可参考VSCode的官方文档),此时终端中显示的路径应为"E:\EXP"
输入命令创建程序文件夹: otree startproject firstexp
在创建文件夹的时候,oTree会问是否Inclued sample games?,输入y并按回车将尝试联网下载样例程序在文件夹中,这些样例程序也可以作为学习的参考,但是由于样例程序可能存放在github或者别的国外平台上,所以由于某些网络原因可能无法成功下载,需要多尝试几次
一般创建程序文件夹不必包括样例程序
一个完整的实验的程序(比如包括不同实验任务和实验后问卷在内)叫做project
按照提示,输入命令将工作路径改至程序文件夹内:cd firstexp
新建的程序文件夹没有具体的实验程序,新建实验程序需要使用命令:otree startapp firstapp 创建新的实验程序文件夹,在oTree中具体某个实验任务(比如偏好测试、问卷)的程序叫做app(有点类似于ztt)
在app文件夹里面,有一个名为_init_.py的文件和MyPage.html、Results.html两个文件,其中.py文件用于实验的后端部分,html文件用于实验的前端部分
程序架构
重要概念:Session、Subsession、Page、Group、Player、Participant
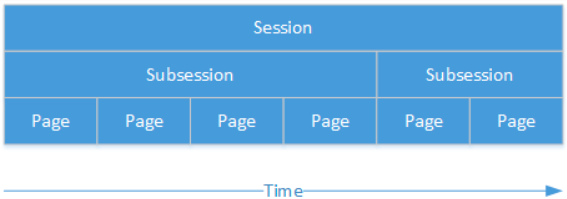
Session在oTree中指的是一场活动(event),这个活动中有许多参加者参加进来完成一系列的任务或游戏,官方文档提供的例子:A number of participants will come to the lab and play a public goods game, followed by a questionnaire. Participants get paid EUR 10.00 for showing up, plus their earnings from the games.
Subsession是Session下的一个概念,多个Subsession组成一个Session,一个Subsession可以理解为某一个实验任务、实验环节等,比如在上面的例子中,一个公共品博弈是一个Subsession,后续的问卷调查也是一个Subsession,这两个共同构成了一个Session
每个Session下又由许多个Page组成,比如公共品博弈中有规则介绍、决策输入、结果报告等page,图示例子参考下一页图片。
Concept Session
如果一个任务重复多次,那么每一轮都看作一个Subsession,比如公共品博弈任务重复10次就是10个subsession
Subsession又可以进一步划分为不同的Group,每个Group里面包含Player。比如在公共品博弈中,20个人平分为4个Group,每个Group5个Player,每个Player都会看到一系列的Page并作出决策。不分组的单人决策情景可以理解为一人一组
Participant意味参加者、被试,与之相对的Player可以理解为角色、身份,在不同的Session和Subsession之间,同一个Participant可以是不同的Player,比如在第一轮中作为委托人,在第二轮中作为代理人
层级排序如下:
- Session(一个Session包含多个Subsession,Participant参加Session)
- Subsession(一个Subsession包含多个Group)
- Group(一个Group包含多个Player)
- Player(一个Player可以看到多个Page)
- Page
- Player(一个Player可以看到多个Page)
- Group(一个Group包含多个Player)
- Subsession(一个Subsession包含多个Group)
从低层级的对象向上获取高层级的对象的字段前需要使用如下写法 player.participant/player.group/player.subsession/player.session/group.subsession/group.session/subsession.session
__init__.py文件的内容可以分为models和pages两部分(旧版oTree中models和pages是两个分开的py文件,新版中合并为一个),models部分有C类(常数类)、Subsession类、Group类、Player类4个类,pages部分中都是Page类
C类下的字段包括关于实验程序的名字、分组人数、轮次数等实验设置相关的字段,也可以添加一些整场实验中需要用到的不变的参数(常见的例子有投资回报率、惩罚成本等等),规范来说,C类下的变量名字全部字母大写
从对象的角度来说,Subsession、Group、Player是不同的类,每个类有不同的字段,从数据的角度来说Subsession、Group、Player可以理解为不同的数据表,每个表的一列就叫做Field,数据就是储存在Field里面,体现为对象的字段
例子:
class Player(BasePlayer):
name = models.StringField() #文本
age = models.IntegerField() #整数
is_student = models.BooleanField() #布尔
每个类下面都有一些内置的字段和方法,表示这个类可以执行的一些任务或功能,关于这些内置的字段和方法以及设定方式请参考官方文档Models一节下面的介绍
从层级来说,Subsession中的数据由同一场次的所有player共享,而Group中的数据则由该组内的Player共享
假如Subsession下有一个字段是cost,那么该场实验中所有player调用player.subsession.cost都是得到同样的数据,无论这个player属于哪一组
假如Group下有一个字段是total加总了所有人的年龄,那么第一组的人调用的player.group.total得到的是本组年龄和,第二组的人调用的player.group.total得到的是本组的年龄和,两个组调用得到的数据是不一样的
pages部分的Page类定义了参加者将看到的页面,page_sequence则定义了这些页面出现的顺序(即定义的先后不影响出现的先后,page_sequence才是控制页面先后顺序的),每一个Page都需要有对应的html文件,否则将会报错
比如定义了一个Page名字叫MyPage并加入了page_sequence中,则必须存在MyPage.html文件,否则会报错
Page类同样有很多的内置方法,比较重要的有is_displayed()、vars_for_template()、before_next_page()等,同样具体的设定方式请参考官方文档Pages一节下面的介绍
有一类特殊的page是WaitPage,是参加者在等待别人决策时可以看到的等待界面,由oTree内置,在需要使用的地方加入page_sequence即可,不用另外建立html文件
html文件是实验的前端部分,在页面上展示什么信息、如何展示都需要在html文件中写入
oTree基于oTree Lite框架提供了简单的Template语法,可以快速排布所需要的信息和元素,写法:
{{ block title }}
收益情况
{{ endblock }}
{{ block content }}
你的收益是{{ player.payoff }}
{{ next_button }}
{{ endblock }}
这个Template语言只是用于快速地展示数值,不能完成任何的计算、赋值、修改等任务,这些任务要么交由后端python完成再传向前端,要么使用JavaScript
使用Template标记的html文件会先交由oTree系统(服务器端)扫描并转化成相应的HTML标记,再交由浏览器(被试端)根据HTML标记展示相应的网页
可以使用HTML、CSS、JavaScript等语言灵活修改,更具体的方法可参考官方文档Templates一节的介绍
3. oTree 运行逻辑
_init_.py文件是管理后端的文件,定义了整个实验的逻辑、计算任务、数据交互等重要内容,也管理着后端与前端的交互和数据传输以及前端的页面顺序等
html文件是前端的文件,给参加者展示了实验任务的具体信息、决策任务、实验结果等内容,一般不进行计算任务、变量赋值和数据修改等
oTree为后端、前端文件的编写以及前后端的交互提供了方便,也为实验数据的储存、参加者的连接等提供了简单的方法,便于快速编写和开展实验
参加者通过浏览器获取经oTree处理的页面,在页面上进行决策,相关数据传回服务器并储存在数据库中,这个交互的过程同样由oTree帮助完成。
原文地址: https://github.com/MarvinLuoGS/otree-crash-tutorial 和 https://slides-otree-tutorial.netlify.app/1 感谢 罗干松 (ZJU) 范徐航(Duke) 同学,如果内容涉及侵权,告知我后会立即删除。
No responses yet